Generative Adversarial Networks
目录
GANs #
Overview
- The-gan-zoo: https://github.com/hindupuravinash/the-gan-zoo?tab=readme-ov-file
- Tips to make GAN works: https://github.com/soumith/ganhacks?tab=readme-ov-file
- Survey of GANs: https://iopscience.iop.org/article/10.1088/2632-2153/ad1f77/meta#mlstad1f77s4
- Famous architecture reproduction: https://github.com/aladdinpersson/Machine-Learning-Collection
- Visualization Tool: GAN Lab
Original GAN #
\(L_{Discriminator} = \nabla_{\theta_d}\frac{1}{m}\displaystyle\sum_{i=1}^{m}[\log{D(x^{(i)})} + \log{(1-{D(G(z^{(i)}))})}]\)
\(L_{Generator} = \nabla_{\theta_g}\frac{1}{m}\displaystyle\sum_{i=1}^{m}\log{(1-{D(G(z^{(i)}))})}\)
Objective Function: #
The goal is to maximize the loss of \(D\) and minimize the loss of \(G\)
Original minmax(zero-sum)
\begin{align} \displaystyle\min_G \displaystyle\max_D {V(D,G)} &= E_{x\thicksim{p_{data}(x)}}[\log{D(x)}] + E_{z\thicksim{p_z(z)}}[\log{(1-D(G(z)))}] \end{align}Which can also be represented in JS divergence format:
\begin{align} C(G) = 2JS(p_{data}\parallel p_g)-2\log2 \end{align} not provide a sufficient gradient for G to learn wellNon-saturating
The non-saturating function results in a larger gradients in early learning process.
\begin{align} E_{x\thicksim{p_g(x)}}[-log{D_G^*(x)}] + E_{x\thicksim{p_g(x)}}[\log{(1-D_G^*(x))}] = KL(p_g\parallel p_{data}) \end{align}Mode collapse: G will prefer to produce repititions but safe examples.
Miximum Likelihood
Under the assumption that the discriminator is optimal, minimizing:
\begin{alignat}{2} J^{(G)} &= E_{z\thicksim p_z(z)}[-exp(\sigma^{-1}(D(G(z))))]\ &= E_{z\thicksim p_z(z)}[\frac {-D(G(z))} {1-D(G(z))}] \end{alignat}

Loss Variant #
WGAN -Wasserstein GANs
- use the Wasserstein distance as the optimization criterion
- objective function: \(W(p_{data},p_g) = \displaystyle\inf_{\gamma \in \prod(p_{data},p_g)}E_{(x,y)\in\gamma}[\parallel x-y\parallel]\) where \(\prod(p_{data}, p_g)\) denotes the set of all joint distributions \(\gamma(x,y)\) whose marginals are \(p_{data}\) and \(p_g\)
- innovation:
the distence moving from real data and generated data
binary classifier –> regression task - key features:
remove the last sigmoid activation layer
remove ’log’ function in the lossweight clipping:enforce the discriminator to be a 1-Lipschitz function by clipping its weight to a fxed range.
replace momentum based optimizer ‘Adam’ with RMSProp or SGD
WGAN-GP -Wasserstein GANs -Gradient norm penalty
- use a gradient penalty to achieve Lipschitz continuity.
- Objective Function: \(L = -E_{x\thicksim p_{data}}[D(x)]+E_{\tilde{x}\thicksim p_g}[D(\tilde{x})] + \lambda E_{\tilde{x}\thicksim p_{\tilde{x}}}[(\parallel\nabla_{\tilde{x}}D(\tilde{x})\parallel_2-1)^2]\) The last one is the added penalty item.
- Innovation: This penalty encourages the gradients of the critic with respect to its inputs to have a norm of 1, which helps stabilize the training process and prevent mode collapse.
RGAN -Relativisitic GANs:
- The idea is to endow GANs with the property that the probability of real data being real \(D(x_r)\) should decrease as the probability of fake data being real \(D(x_f)\) increases
- Objective Function: \(D(\tilde{x}) = \sigma(C(x_r)-C(x_g))\)
- Innovation: make the output of D depend on both real and generated examples
- Key features:
- provide continuous measure of the quality of the generated data, by using the relativistic discriminator as the loss function
- improve the stability and robustness of the training process, by avoiding the problems of vanishing gradients, mode collapse, and non-convergence
F-GAN -f-divergences
- Use a general class of divergence functions as the optimization criterion.
- Innovation: provide a unified framework for different GAN variants comparision GAN, WGAN, LSGAN and so on by showing equivalence to different f-divergences.
- Key features:
- can use any f-divergence: KL-divergence, JS-divergence, Total Variation Distance and so on.
- improve the quality and diversity of the generated data by choosing the appropriate f-divergence that suits the data characteristics and the model objectives
Architecture Variant #
Network Architecture #
Original GANs use multi-layer perceptrons(MLPs), so only for small datasets.
DCGAN -deep convolutional generative adversarial networks
- innovation: G and D are defined by deep convolutional neural networks(DCNNs)
- key features:
all-convolution net;
batch normaliztion except the last layer;
use Adam optimizer instead of SGD
PROGAN -Progressive Growing of GANs
- The idea is to grow both the generator and discriminator progressively: starting from a low resolution, we add new layers that model increasingly fine details as training progresses.
- innovation: progressively growing training approach
- key features:
Gradually increasing the resolution
Minibatch Discrimination
Pixel-wise normalization, spectral normalization
orthogonal regularization
SAGAN: self-attention GAN
- SAGAN stands for Self-Attention Generative Adversarial Network, which is a variant of GANs that uses self-attention mechanism to capture long-range dependencies in images and generate high-quality and high-resolution samples.
- innovation: Self-attention mechanism
- key features:
spectral normalization: improves diversity
orthogonal regularization: stability
conditional batch normalization: adjust the style and features
Latent Space #
CGAN -Conditional GANs
- D and G are conditioned on extra information y: \(\displaystyle\min_G \displaystyle\max_D V(D,G)\) \(= E_{x\thicksim{p_{data}(x)}}[\log{D(x|y)}] + E_{z\thicksim{p_z(z)}}[\log{(1-D(G(z|y)))}]\)
- innovation: G and D need to match a given condition
- key features:
generate data matches a given condition
learn a conditional distribution, more informative and useful
can apply to various types of tasks
INFOGAN - information maximizing GAN
- \( \displaystyle\min_G \displaystyle\max_D V_I(D,G) = V(D,G) -\lambda I(c;G(z,c))\), G(z,c) is the generated example, I is the mutual infomation. Maximizeing I maximizes the mutual information between c and G, causing c to contain as many important and meaningful features of the real examples as possible.
- innovation: latent factors
- key features:
Unsuperviesed manner
Discover and munipulate latent factors of semantic attributes
lower bound to approximate \(P(c|x)\)
ACGAN -Auxiliary Classifier GANs
- incorporate a classifier as part of the discriminator, produce recogmozable examples
- Objective functions:
The log-likelihood of the correct source \(L_s\) and correct class \(L_c\), the aim is to maximize \(L_c+L_s\) and \(L_c-L_s\)
\(L_s = E[\log P(S=real|X_{real})] + E[\log P(S=fake|X_{fake})]\)
\(L_c = E[\log P(C=c|X_{real})] + E[\log P(C=c|X_{fake})]\)
innovation: generate data matches the given class label
key features:
add conditional information y into the discriminator
learn conditional distribution of the data
leverage the supervised infomation from the class labels and unsupervised information from the GAN object
SGAN -Stacked GAN
- use a top-down stack of GANs to generate data from hierarchical representations
- innovation: progressively adding finer details at each layer of the stack
- key features:
capture different levels of abstraction and variation(more diverse representation)
can leverage the pre-trained discriminative network(VGG, ResNet) without additional supervision
Application Focus #
SRGAN -Super-Resolution
- use a perceptual loss function to generate high-resolution images from low-resolution images
- innovation: upscaling factors to infer photo-realistic natural images
- key features:
- The perceptual loss function consists of an adversarial loss and a content loss, based on the pre-trained VGG network.
- capture the fine textures and details of the natural images
- upscaling: use a deep residual network with skip connections and sub-pixel convolution layers
- further improvement:
ESRGAN(Enhanced SRGAN)
cycle-in-cycle GANs(unsupervised image SR)
SRDGAN(learn noise)
TGAN(explore tensor structure)
CycleGAN
- image-to-image translation between unpaired domains

- innovation: Use a cycle consistency loss that enforces the generator to reconstruct the original img from the translated img.
- key features:
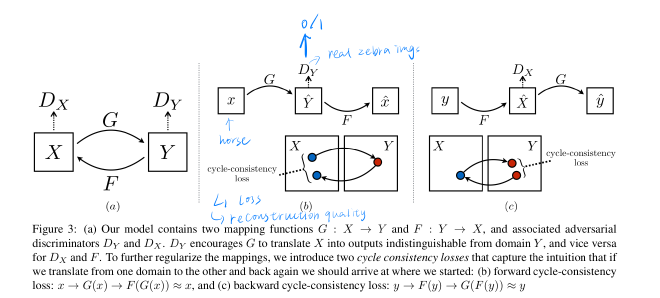
- no paired examples needed
- preserve the key attributes and structures of the input imgs
- learn a mapping function that is bijective and invertible
- application:
- Style Transfer, object transfiguration, photo enhancement
- image-to-image translation between unpaired domains
StyleGAN
- use adaptive instance normalization to control the style and features of the generated images at different scales
- innovation: learn an unsupervised separation of high-level attributes
- key features:
- It can enable intuitive and scale-specific control of the synthesis, by manipulating the style vectors that correspond to different levels of detail.
- add noise makes it more detailed
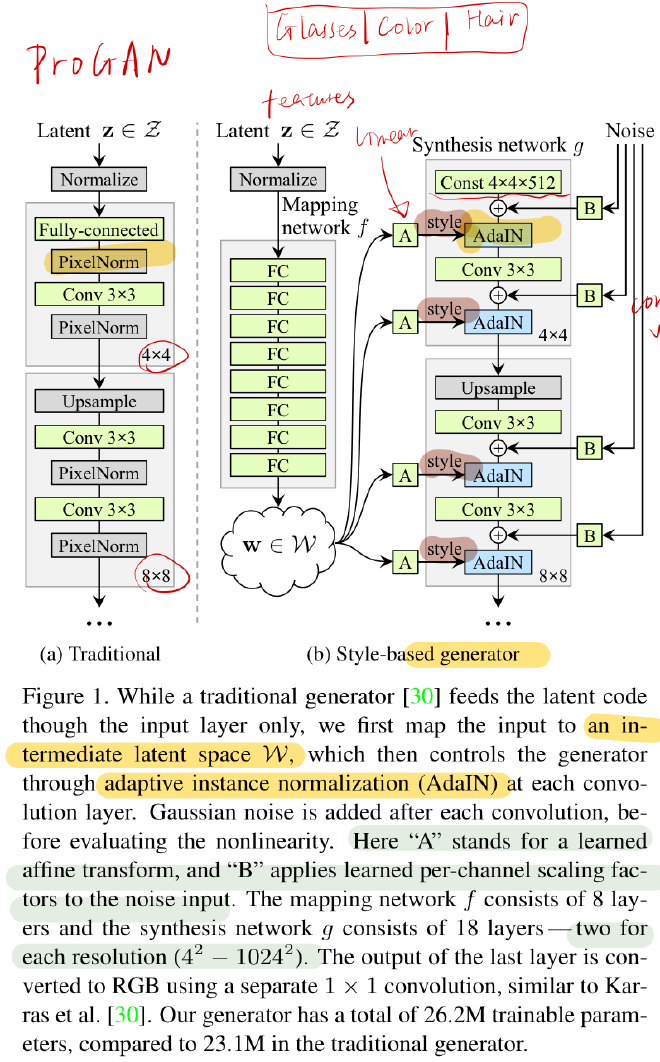
Pix2Pix
- use a conditional GAN objective combined with a reconstruction loss, which are based on the features extracted by a pre-trained VGG network.
- innovation: translate images from one domain to another using paired examples like edges or maps
- key features:
- preserve the key attributes and structures of the input images
- use a U-Net-Based generator with skip connections
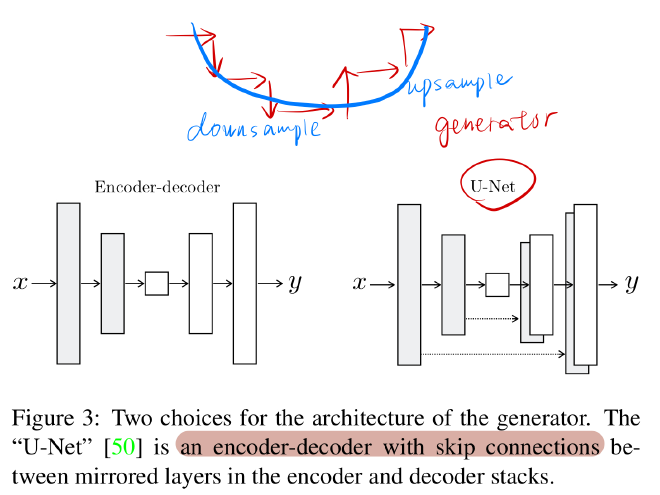
- use a patchGAN-based discriminator
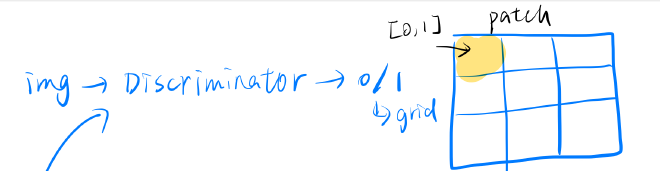
- applications:
- style transfer, object transfiguration, photo enhancement, and more




